Graph databases. Beyond the hype


Lately I have been reading, testing and discovering a lot around graph databases: what they are and what they are not.
First let’s cut the hype, graph databases are not a silver bullet (like nothing is) and they do not provide an advantage or have an angle on all of the use cases, on the contrary they have a few cases when they excel. But on those ones... they are brilliant.
On the company I am working, we have quite an interesting landscape: different tech hubs across Europe, different platforms with very different stacks due to different company acquisitions and, most important, very difficult company cultures that often collide. Ah, and something else: tons of legacy (real one, more than 30 years applications with many evolution layers ...).
One of our goals is to push for one team and one platform to serve our customers needs. Easier said than done of course.
When our product teams started to collaborate across locations and former company boundaries many times they got stuck because there was a lack of understanding or knowledge of some services or business context.
When information is not clear nor easy to retrieve leads to uncertainty and, of course, slows down dramatically team performance and autonomy.
Team autonomy leads to ownership that leads to care.
We started working with the concept of a unified service catalog, where we could index all of the company services (technical), their scope, documentation, ownership rules, api information, etc... so could serve as a single point of truth and reference.
Information is only valid if it’s updated and reliable. In that context, and knowing the infamous love for writing documentation that developers have, of course we could not rely on “gentlemen word” of keeping the catalog up to date. We were needing automation.
Once we had an idea of the problem we wanted to solve and some specific use cases we started designing the information architecture. Of course general approaches for structuring data rely on the domain knowledge of the designer/s so they can foresee the kind of questions that will need to be answered with the stored data.
If for example we would like to know the answer to a question like “how many houses does peter have” and, the information was stored on a regular relational database, we will probably have two entities (people and houses) with a relation between them. On traditional RDB relations do not have a specific meaning, meaning is given by the interpretation and the domain knowledge of the database consumer.
Let me explain better this extending the example, it will be very dumb and trivial by I hope it serves my illustration purpose.
With a traditional relational database
# table people
Id
Name
Lastname
Email
# table houses
Id
Owner_id
Address
Price
With the above example let’s make some analysis.
- If you look at data in the table “people” isolate, you don’t really know if Ane specific person owns any house.
- If you look to the data in the table “houses” you will see a house and if it has an owner_id you will asume that the house has an owner but you will not know owner information until you cross it with the information on the “people” database.
For crossing the data between both tables two things needed to happen.
- The designer of the data store intentionally created a relation between both entities.
- The designer of the entity gave meaning to the relation by giving the name “owner_id” to the field closing the relation. (Foreign key)
- By looking at the structure you are not certain if one person can own more than one house.
- The consumer of the data (the person that needs to answer the question) needs to know that owner_id is the relation with another table name people and refers to its if field. Of course this can be improved with field naming but as explained implies a specific knowledge of the consumer to do the crossing.
Once our system gets more detailed and we need to answer to more complex questions, data architecture also gets more complex and we keep relying that the savy database architect created the needed relations so the structure is ready to solve any question consumer might need in the future.
Of course one of the benefits of RDB is that schema can be updated and it’s change will affect all of the records on the database and we can rely on incremental design.
Anyway, expertise in the design and on the consuming processes will be needed for a correct data analysis.
With a graph database
On graph databases we don’t store records on a table, data is stored in nodes. Nodes are, like in nosql databases, collections of structured data (usually just key-value pairs).
Nodes can have types that are defined by “labels”. In graph databases relations (edges) have a semantically correct meaning and are as important as node data itself. Relations can also have properties (structured data).
So following our example we could have an structure like this.
# Node label: person
id: 'JohnSmith'
name: John
lastname: Smith
email: john@example.com
# Node label: house
id: 'villa-bonita-33'
address: '1 awesome road, Metropolis'
price: 1000000
# Relation
JohnSmith — (OWNS) —> villa-bonita-33
# And even relation could have enriched information like
JohnSmith — (OWNS)[since:01-01-1990] —> villa-bonita-33
And of course represented in a graph like this:
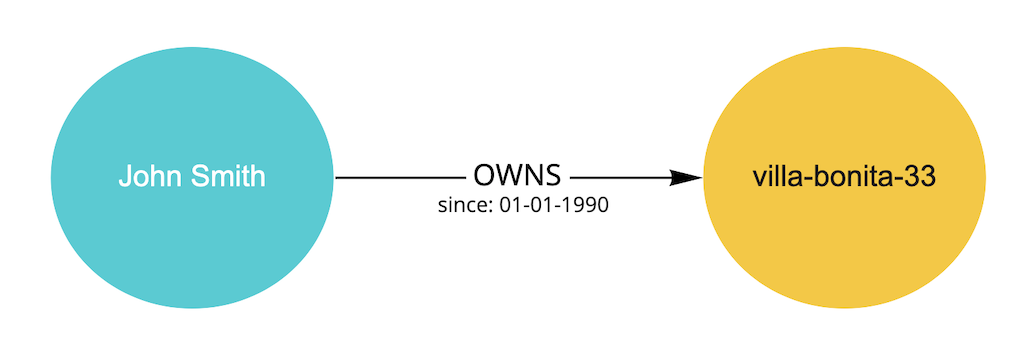
If we do the same analysis we did with the RDB example.
- You can read the data and the relation without needing to have the domain knowledge. It is self explanatory and implicit.
- Like nosql schemaless databases, each node can contain different data with more or less properties. One node will contain only the relevant information and no empty data. On a traditional RDB when record is missing information is not clear if it’s by design or a data inconsistency.
- Visualization of the data makes analysis easier.