Service catalog - Automating documentation


More than a year and a half ago I wrote a post "Graph databases. Beyond the hype" where I was explaining what were graph databases and how we were leveraging them to solve a problem around knowledge sharing and service documentation. I promised to continue the explanations but I failed to do until now. I had posted some information on our internal blogs but did not share it outside.
I believe it's interesting to share what we have done and how we are "scratching our own itch".
This has been one of my side projects during the last year, I apologize beforehand for the long post. 😂
Why?
In our group, we have a complex ecosystem, both in technology and in teams. It was difficult to find information around our services and trickier to try to build a standard for documenting when dealing with so different stacks, teams, and even development cultures. Knowledge is key in effective collaboration. Often teams get stuck or slowed down by lack of information, misinformation or simply blurriness on information and the answer for many questions is: I don’t have a clue. That's why created " Clue" an internal product to allow people to find the information they need around their services.
Since we started the project I have written several articles and pieces of information around it so here I would try to aggregate and summarize the content to depict how this works.
There were also three main premises that we had in mind when approaching the challenge.
- Developers are not great documenters. For documentation to be updated it will need to live as close to the code as possible.
- Automation, automation, automation. All of the processes for building the catalog should be automated to have up-to-date and relevant information.
- Needs to bring value! To encourage developers to add documentation around the services and use the platform, they need to perceive the value it brings. This is the best motivator for teams.
We want that each technical service/component has a responsible team that will be guaranteeing that the service is evolving correctly and stays maintainable, performant, and secure. It does not mean that only the responsible team can contribute with code to the service. Any team that needs it could propose changes to the service. Changes will be always be validated by the maintainer team.
What have we built?
For the above premise to be possible we needed to have in place two things:
- A clear service catalog that gives clarity of what team is responsible for each service as well as the scope for each service.
- Technical & functional documentation around the service.
- A clear procedure with the “rules of engagement” of what is the process when a team needs to do evolutions/extensions of a service/component that is not maintained by them.
Clue UI is an interface to be able to interact with the graph database. We have some custom screens around our services and teams and also we allow to query directly the database with "cypher" (Neo4j query language) for answering more complex questions and also do deeper architecture analysis.
I will show some screenshots to illustrate some features of the platform that I hope spike your curiosity. The screenshots are the details for a specific service in the catalog. They are the details for the "Clue" service.
Service overview
The idea of this set of features is to have a 360 view of information around a service.

List services in the database
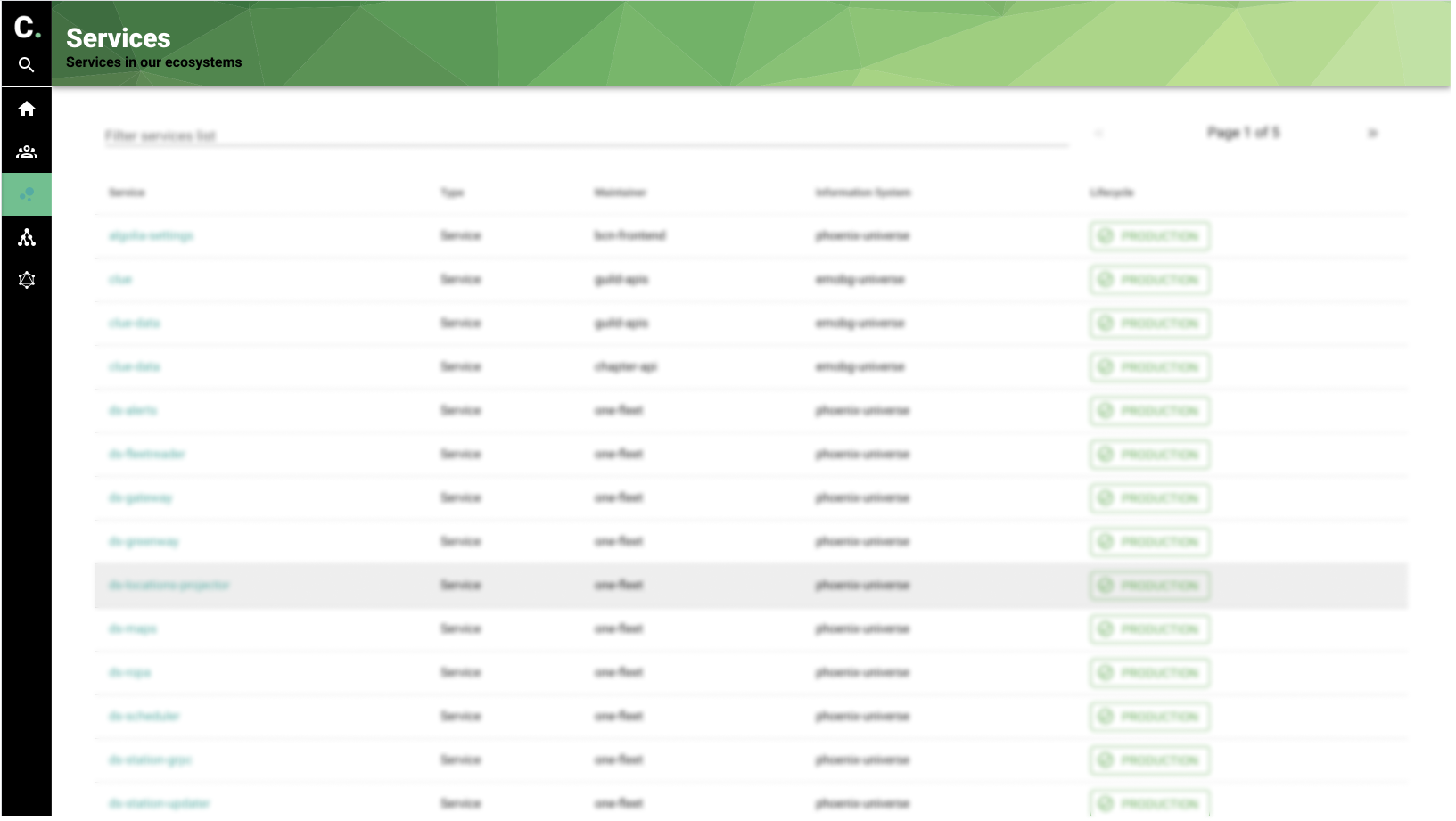
Selected service overview screen. Sections of the service details are different depending on the service type

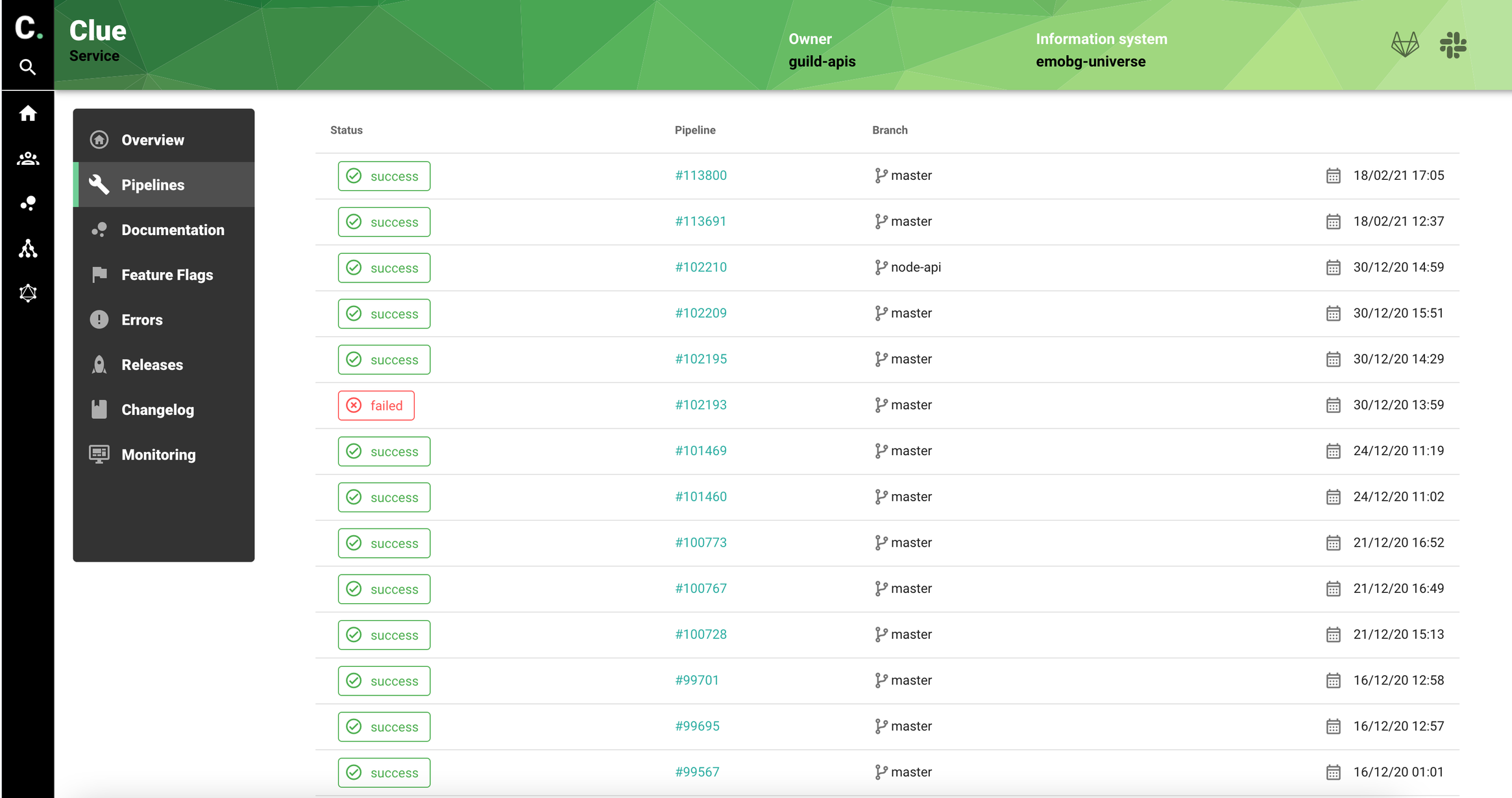
We display pipeline status for the service using Gitlab API
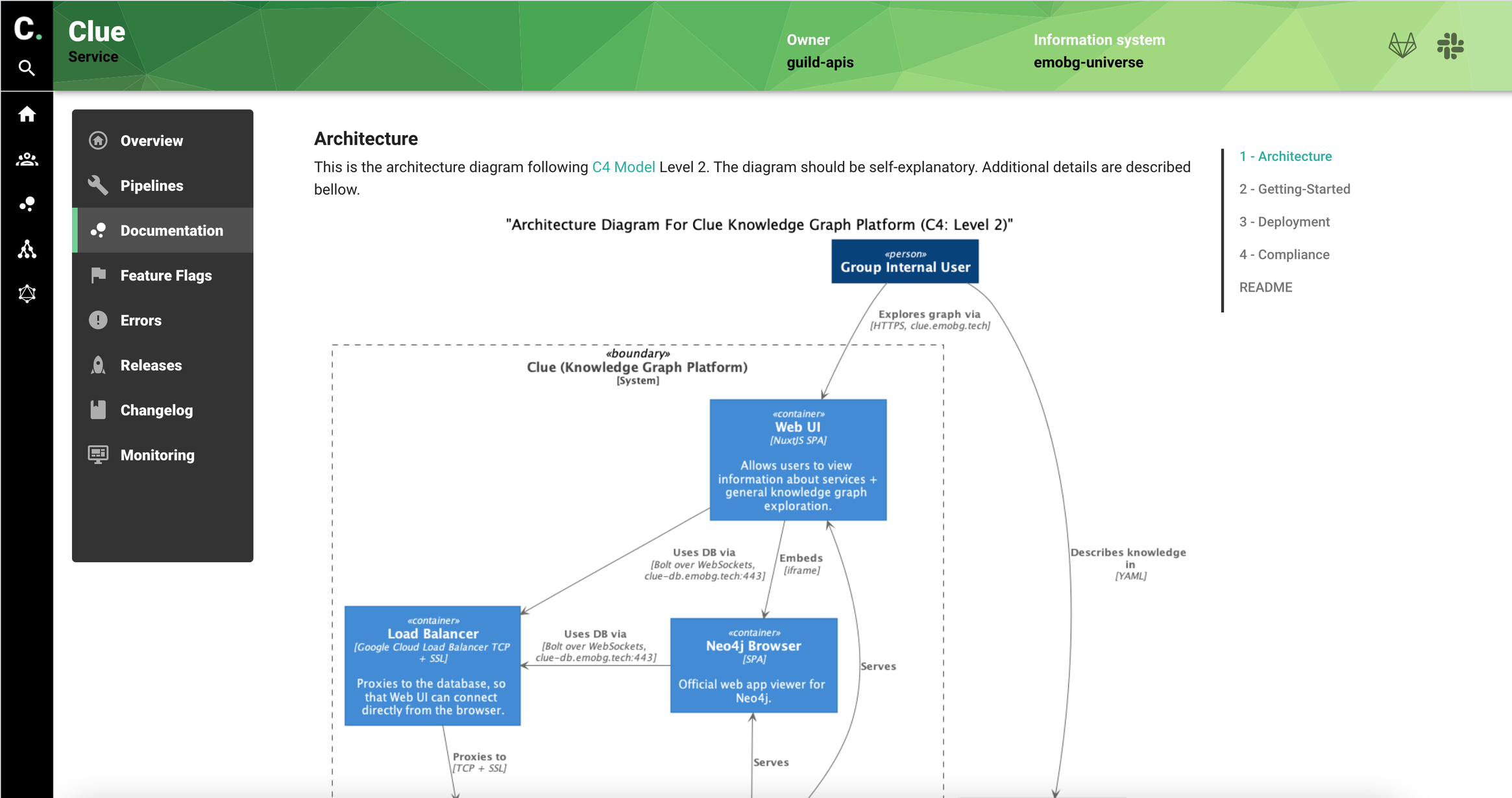
Documentation rendered directly using gitlab API. We display all markdown files on the documentation folder for the service
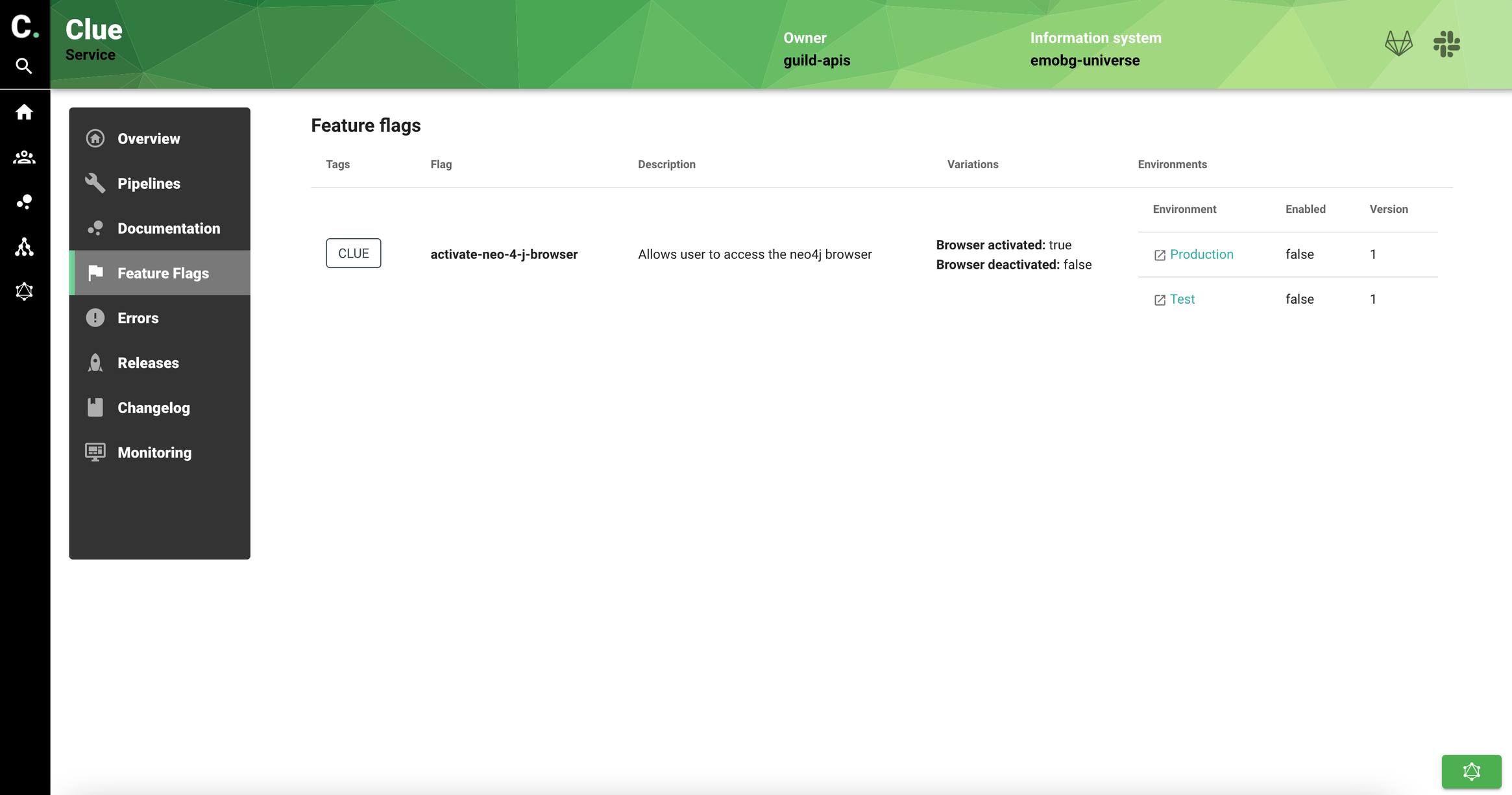
We display feature flags and status for the service using Launchdarkly API
Errors reported for the service on Sentry
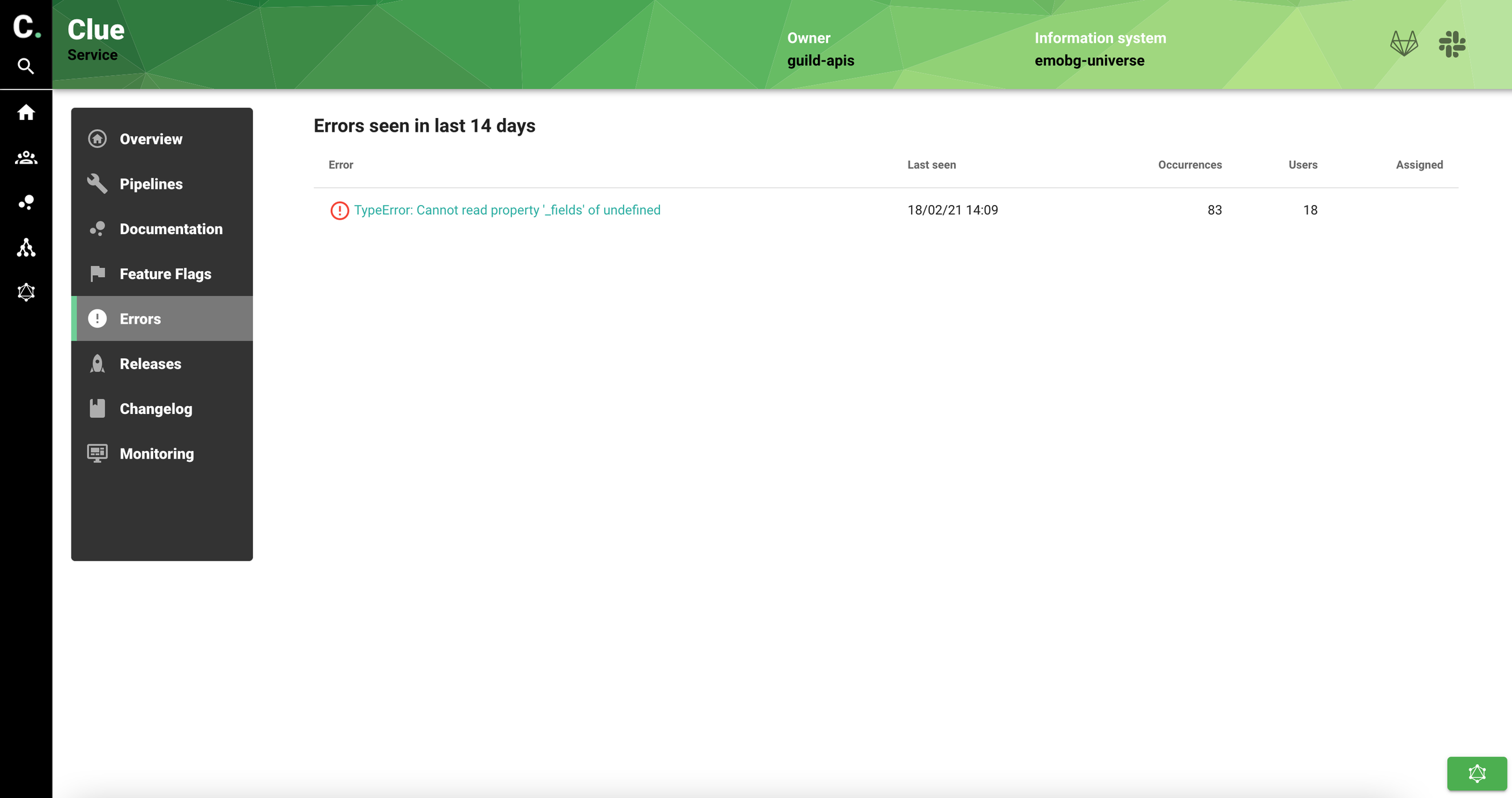
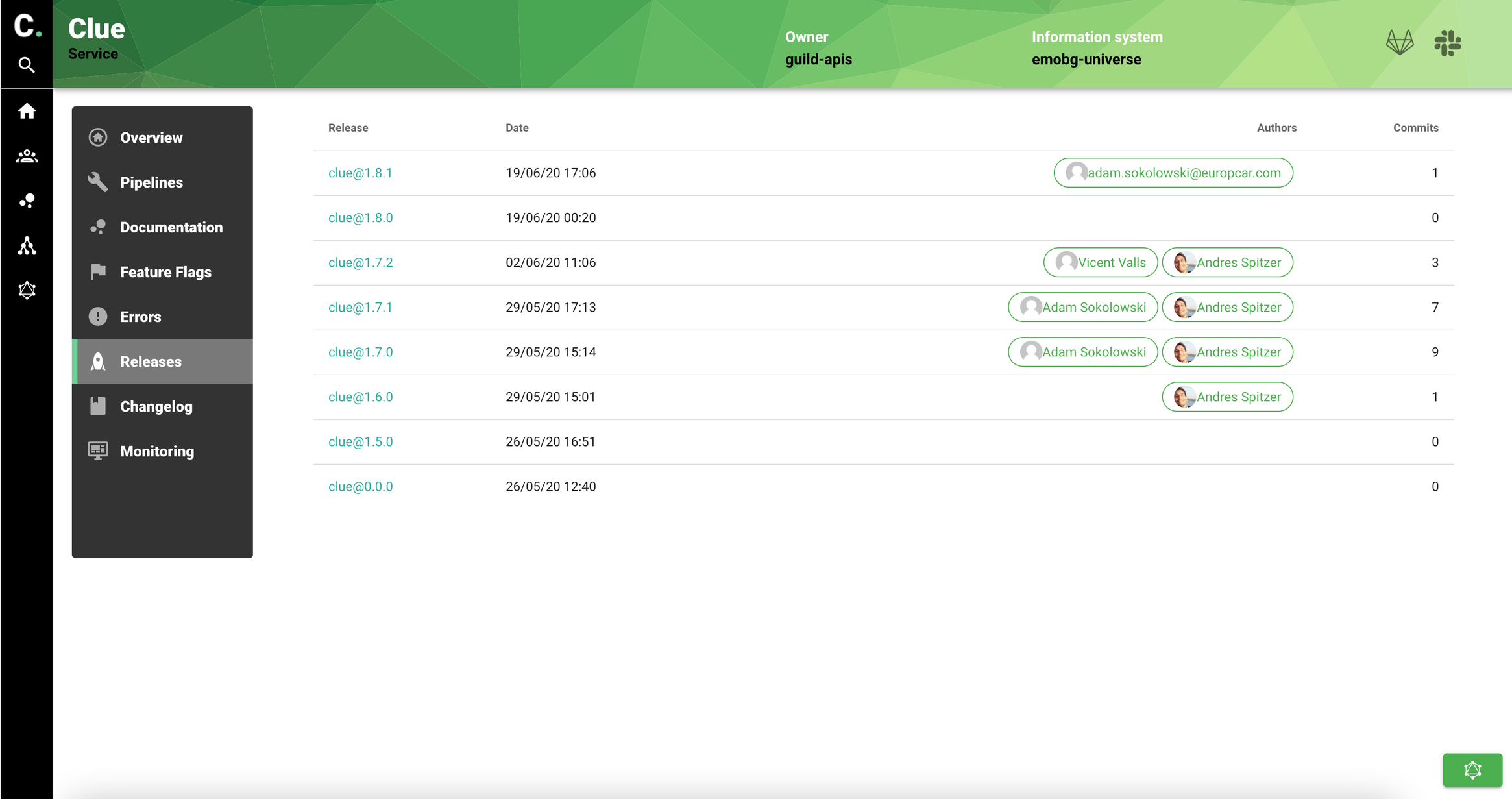
We also track releases for the service using Sentry release feature
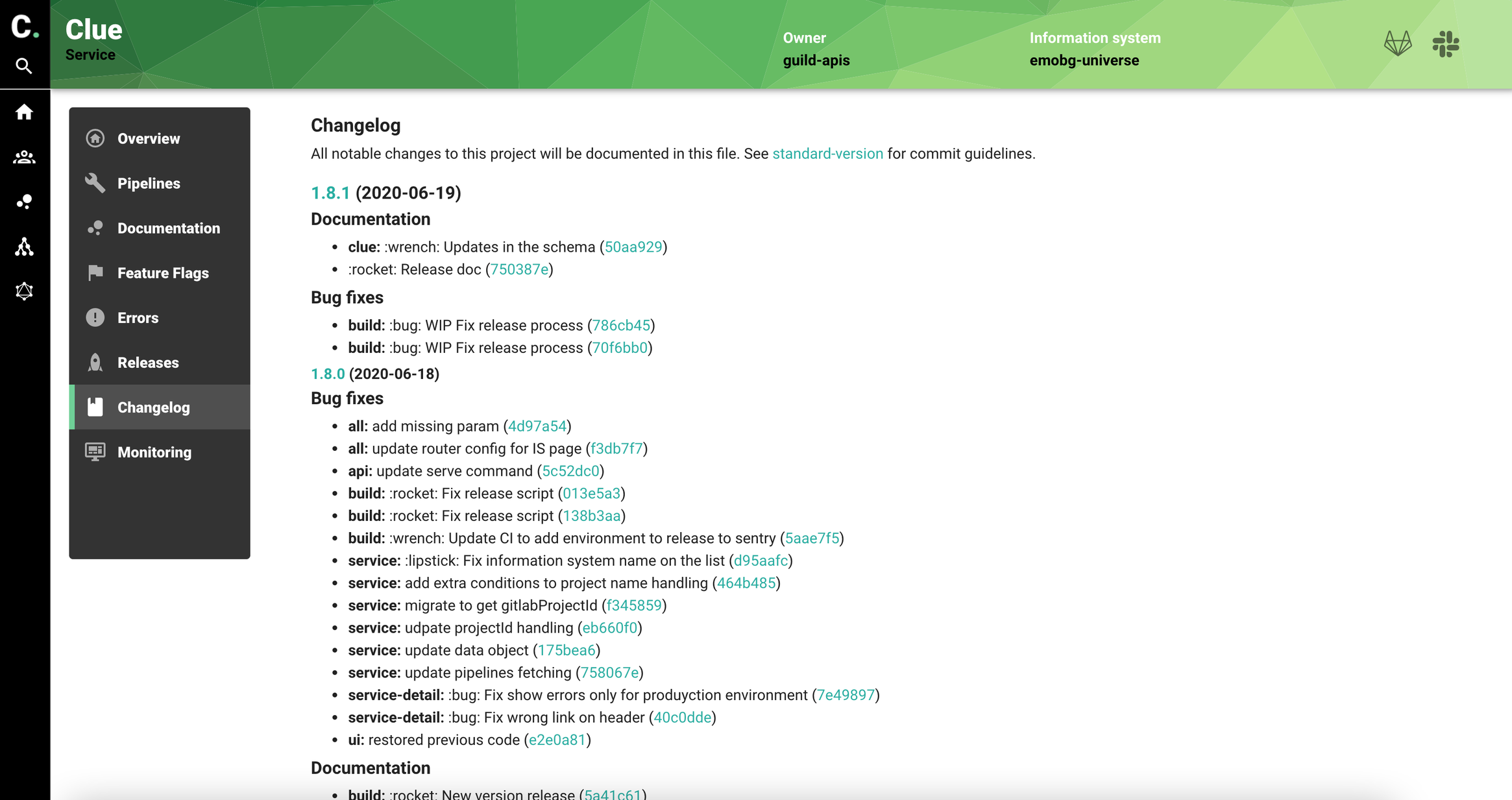
Changelog file is build automatically on the release process and also displayed using Gitlab API
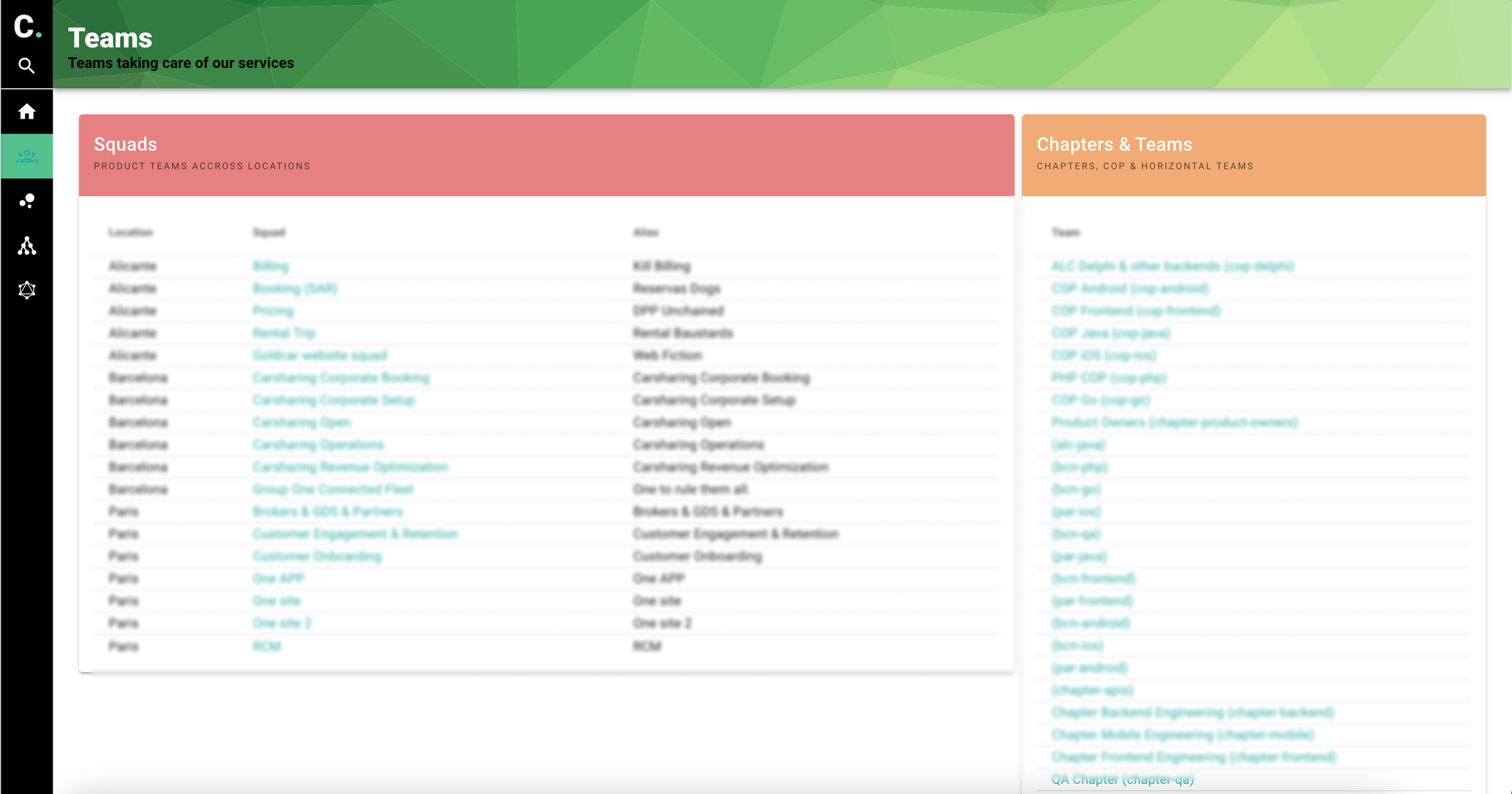
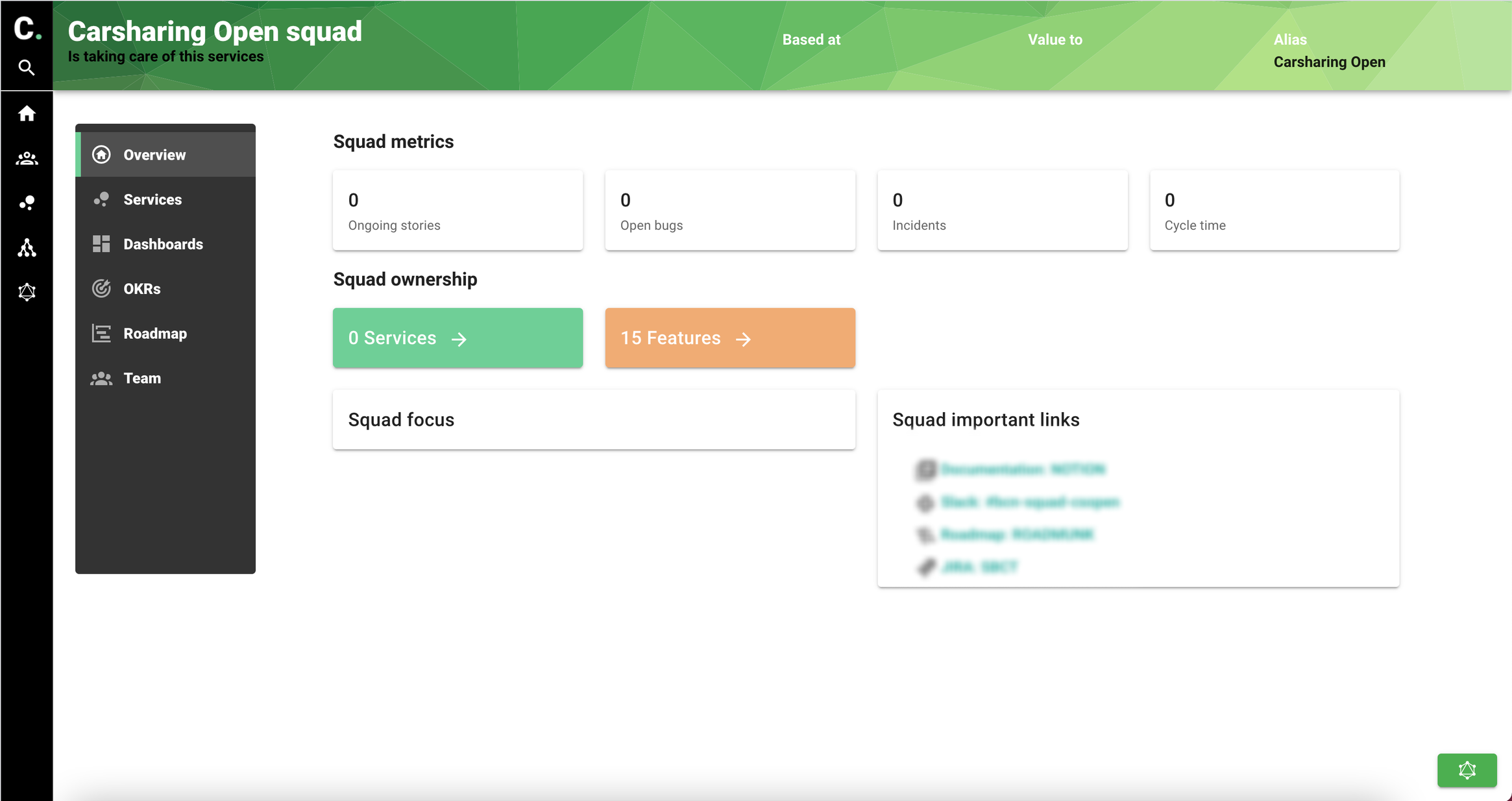
Team overview
Have 360 view around a team. Services, features, OKRs...
List teams in the database
Team overview
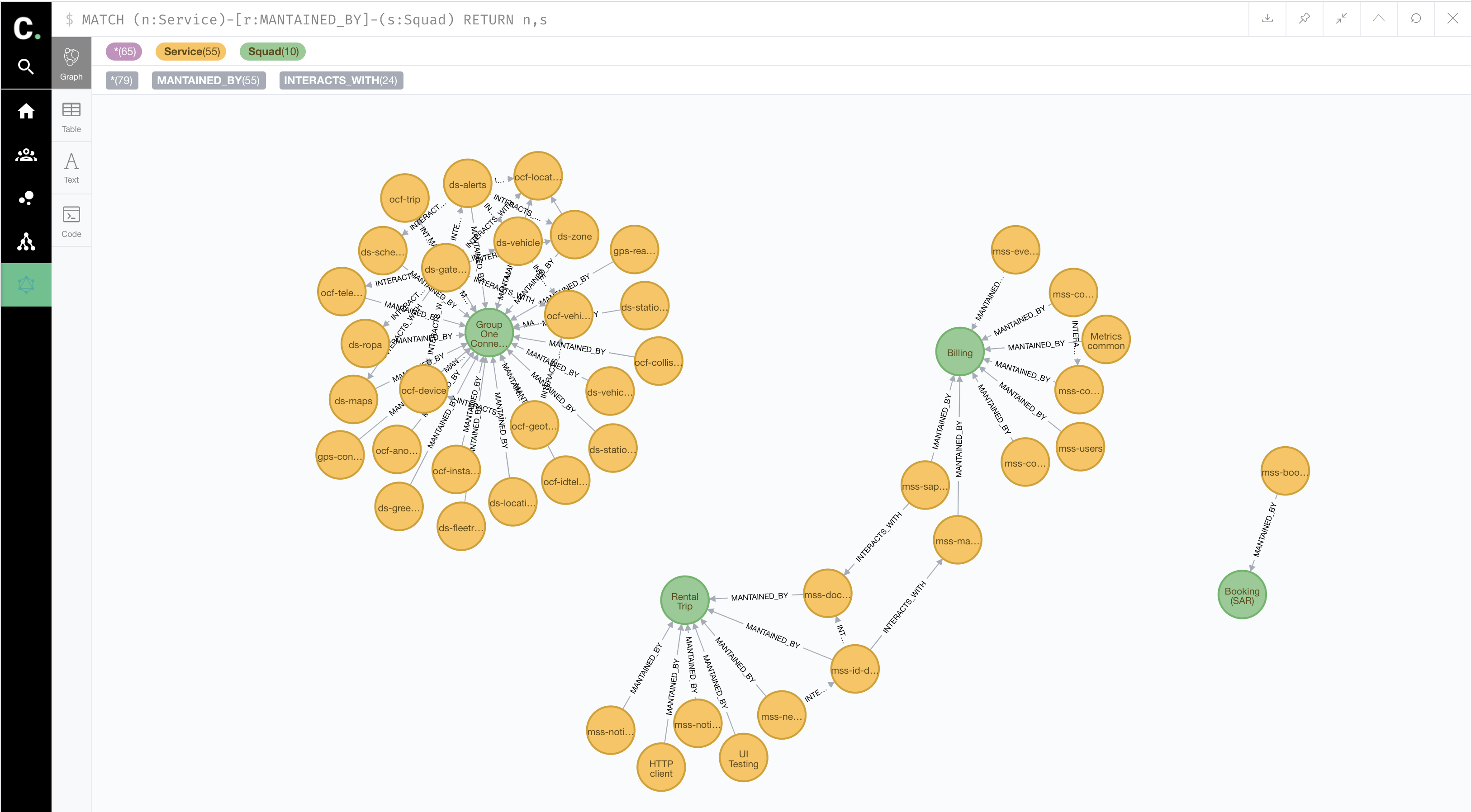
Advanced queries
We also have embedded the neo4j browser where user can make more concrete and complex questions directly to the database.
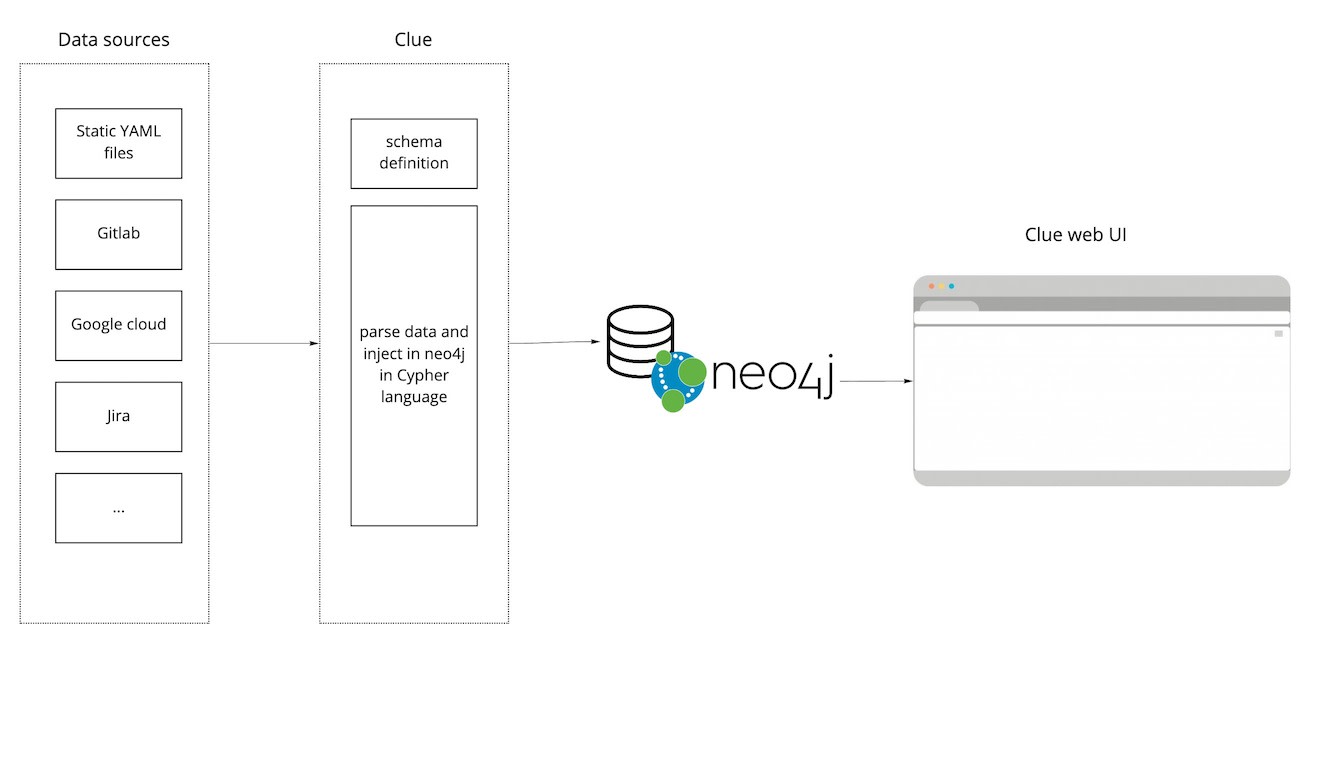
How does it work?
As we explained at the beginning of the post, the idea was to have the catalog as automated as possible. So we built a service that automatically scans different information sources and inserts the relevant information to the database according to a defined schema. Let's see a high level view of the architecture.
Knowledge graph
The information in the catalog is stored in a graph database that is the perfect match for managing complex knowledge graphs. The idea is to be able to store all the documentation and meta-information around all of the entities that are relevant.
This knowledge graph can become very complex and wide so I will start explaining here some of the foundations of how the information is structured and related.
Software elements entities
As part of the knowledge base, there are several software-related elements with different granularities that are related between them and will help describe our ecosystem which is still today composed of very different information systems
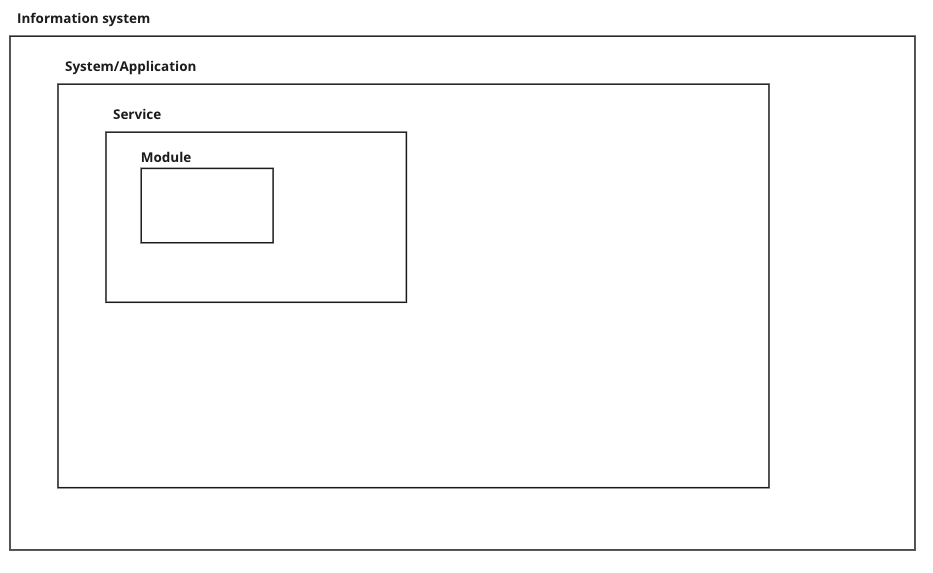
So on our catalog, we will have entities created with the different granularity levels and there also will be the relation between them as illustrated in this example:

Each of those entities will follow a defined schema that is validated automatically by our Clue CLI and will describe with as much detail as we want the properties of the entity as well as the relations the entity has.
This is an example of a service description on a YAML file. You will see that we describe the service’s basic metadata as well as its relations with other entities. We store this yaml fileon each service repository, and then its automatically scanned periodically by our Clue importer service.
label: Service
items:
clue:
title: clue
serviceType: MONOLITH
description: "<b>Clue Service & UI:</b> Please go to Documentation...
"
sourceCode: "https://gitlab-url-goes-here"
gitlabProjectId: projectId
documentationFolder: "clue"
exposesApi: NONE
showInGraphs: BOTH
capabilities: ""
deploymentConfigUrl: ""
runtimeConfigUrl: ""
changelogPath: CHANGELOG.md
logsUrl: ""
healthUrl: ""
metricsUrl: ""
errorTrackingTool: SENTRY
errorTrackingId: "12345"
releaseServiceName: "clue"
errorTrackingUrl: "https://errortracking-url"
codeAnalysisTool: SONAR
codeAnalysisUrl: ""
featureFlagsTool: LAUNCHDARKLY
featureFlagsUrl: "https://flagsservice-url"
featureflagsProject: clue
featureFlagsTag: CLUE
continousIntegrationTool: GITLAB
lifecycle: PRODUCTION
slaCriticalityLevel: A1
slaOperationRange: OR1
slaRecoveryTimeObjective: C1
slaRecoveryPointObjective: D1
relations:
- type: PART_OF_INFORMATION_SYSTEM
to: InformationSystem=emobg-universe
- type: MANTAINED_BY
to: Guild=guild-apis
- type: USES_LANGUAGE
to: ProgrammingLanguage=go
- type: USES_LANGUAGE
to: ProgrammingLanguage=javascript
- type: USES_FRAMEWORK
to: Framework=nuxt
- type: USES_STORAGE
to: Storage=neo4j
showInGraphs: TECHNICAL
- type: DEPLOYED_AT
to: Infrastructure=gcp
- type: DEPLOYED_ENVIRONMENT
to: Environment=production
properties:
url: "[UI](https://exposed-url)"
If you see, on this file we describe the service as entity "label: Service". This means we will use the "service" schema to parse and validate the content of the file and insert in on the neo4j database. This is the schema definition for the service entity.
enum ServiceTransport {
REST
GRPC
MESSAGE
TCP_SOCKET
}
enum Lifecycle {
PRODUCTION
DEVELOPMENT
TO_DECOMISSION
DECOMISSIONED
}
enum ServiceType {
MONOLITH
MICROSERVICE
FRONT_ONLY
DAEMON
BATCH
}
enum ShowInGraphs {
TECHNICAL
BUSINESS
BOTH
}
enum ErrorTrackingTool {
SENTRY
OTHER
NONE
}
enum CodeAnalysisTool {
SONAR
OTHER
NONE
}
enum FeatureFlagsTool {
LAUNCHDARKLY
OTHER
NONE
}
enum ContinousIntegrationTool {
GITLAB
BITRISE
JENKINS
NONE
}
enum ExposedApi {
NONE
REST
SOAP
GRPC
}
type Service {
id: String!
serviceType: ServiceType
showInGraphs: ShowInGraphs
title: String
description: String
documentationFolder: String
exposesApi: ExposedApi
capabilities: String
sourceCode: String
gitlabProjectId: Int
deploymentConfigUrl: String
runtimeConfigUrl: String
changelogPath: String
logsUrl: String
healthUrl: String
metricsUrl: String
errorTrackingTool: ErrorTrackingTool
errorTrackingId: String
errorTrackingUrl: String
releaseServiceName: String
codeAnalysisTool: CodeAnalysisTool
codeAnalysisProject: String
codeAnalysisUrl: String
featureFlagsTool: FeatureFlagsTool
featureFlagsUrl: String
featureflagsProject: String
featureFlagsTag: String
continousIntegrationTool: ContinousIntegrationTool
costCenter: String
lifecycle: Lifecycle
featuresDocProjectId: Int
featuresDocfolder:String
slaCriticalityLevel: SlaCriticalityLevelEnum
slaOperationRange: SlaOperationRangeEnum
slaRecoveryTimeObjective: SlaRecoveryTimeObjectiveEnum
slaRecoveryPointObjective: SlaRecoveryPointObjectiveEnum
}
union ServiceModuleApp = Service | Module | MobileApp | WebApp
union ServiceModuleAppFeature = Service | Module | MobileApp | WebApp | Feature
union ServiceModuleSystem = Service | Module | MobileApp | WebApp | System
# This relation is set automatically by clue-gitlab-importer.
type InRepository @relation(name: "IN_REPOSITORY", kind: MANY) {
from: ServiceModuleApp
to: CodeRepository
}
type PartOfInformationSystem @relation(name: "PART_OF_INFORMATION_SYSTEM", kind: UNIQUE) {
from: ServiceModuleSystem
to: InformationSystem
}
type UsesLibrary @relation(name: "USES_LIBRARY", kind: MANY) {
from: ServiceModuleApp
to: ExternalLibrary
}
type MantainedBy @relation(name: "MANTAINED_BY", kind: UNIQUE) {
from: ServiceModuleApp
to: Team
}
type ResponsibleChapter @relation(name: "RESPONSIBLE_CHAPTER", kind: UNIQUE) {
from: ServiceModuleApp
to: Team
}
type ResponsibleTeam @relation(name: "RESPONSIBLE_TEAM", kind: UNIQUE) {
from: ServiceModuleApp
to: Team
}
type DeployedBy @relation(name: "DEPLOYED_BY", kind: MANY) {
from: Service
to: Team
}
type DeployedAt @relation(name: "DEPLOYED_AT", kind: MANY) {
from: Service
to: Infrastructure
project: String
}
type DeployedEnvironment @relation(name: "DEPLOYED_ENVIRONMENT", kind: MANY) {
from: ServiceModuleApp
to: Environment
url: String
}
type UsesFramework @relation(name: "USES_FRAMEWORK", kind: MANY) {
from: ServiceModuleApp
to: Framework
version: String
}
type UsesSaaS @relation(name: "USES_SAAS", kind: MANY) {
from: ServiceModuleAppFeature
to: Saas
showInGraphs: ShowInGraphs
}
type UsesLanguage @relation(name: "USES_LANGUAGE", kind: MANY) {
from: ServiceModuleApp
to: ProgrammingLanguage
version: String
}
type UsesStorage @relation(name: "USES_STORAGE", kind: MANY) {
from: ServiceModuleApp
to: Storage
database: String
showInGraphs: ShowInGraphs
}
type InteractsWith @relation(name: "INTERACTS_WITH", kind: MANY) {
from: ServiceModuleApp
to: Service
transport: ServiceTransport
showInGraphs: ShowInGraphs
}
type InteractsWithBroker @relation(name: "INTERACTS_WITH_BROKER", kind: MANY) {
from: ServiceModuleApp
to: MessageBroker
# For multiple topics separate with commas, i.e. "topic-1,topic-2,topic-3".
readTopics: String
writeTopics: String
}
type InteractsWithQueue @relation(name: "INTERACTS_WITH_QUEUE", kind: MANY) {
from: ServiceModuleApp
to: QueueSystem
# For multiple topics separate with commas, i.e. "topic-1,topic-2,topic-3".
consumeQueues: String
putInQueues: String
}
type InDomain @relation(name: "IN_DOMAIN", kind: MANY) {
from: ServiceModuleApp
to: BusinessDomain
}
type ImpactsInitiative @relation(name: "IMPACTS_INITIATIVE", kind: MANY) {
from: ServiceModuleApp
to: Initiative
}
Relating to other entity types
There are several types of entities and not all are describing software elements. This gives us the hability to describe very complex systems on a very easy way.
So, the graph can start describing the entity on a much more richer way, like this:
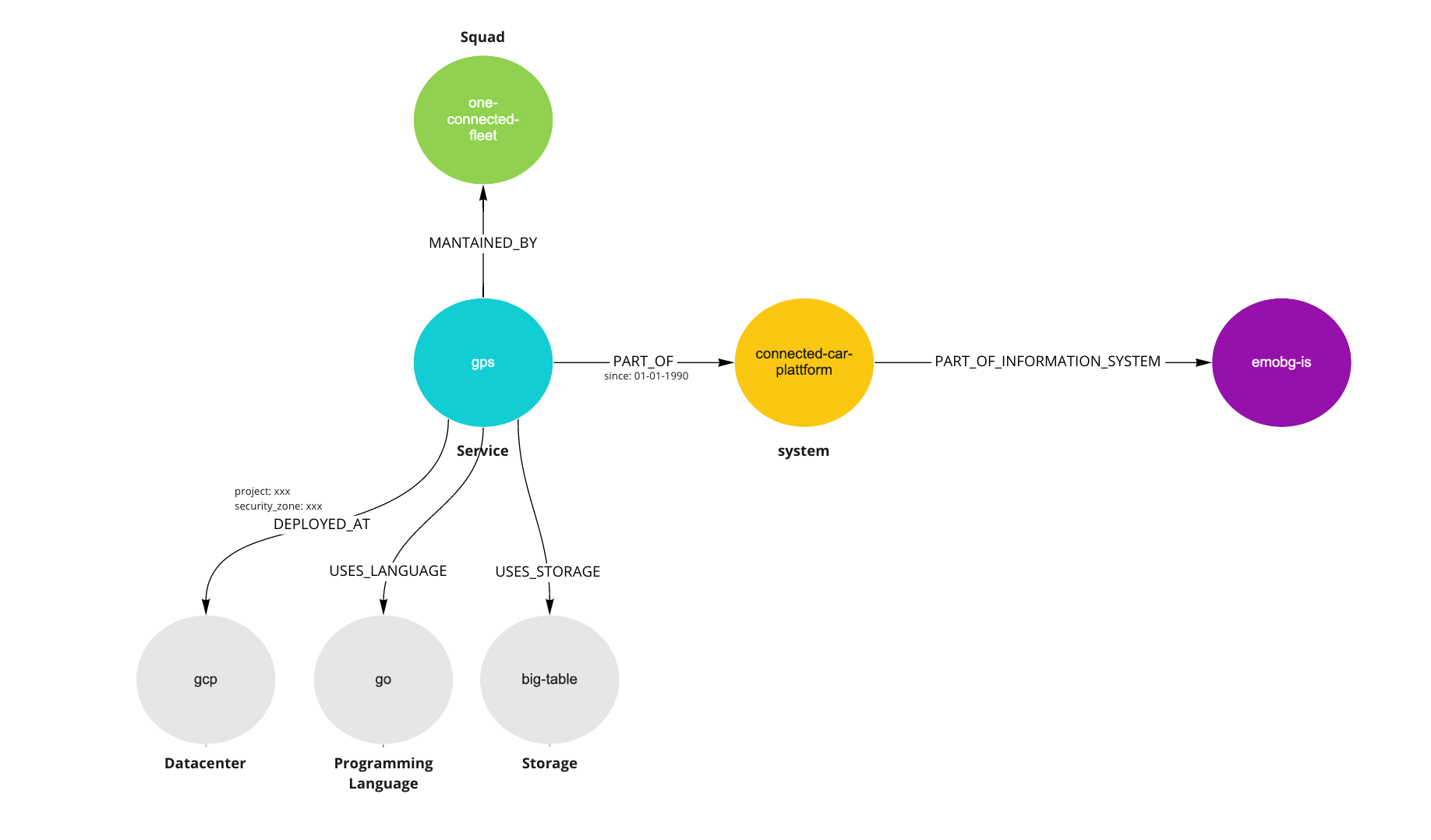
Of course, each of those related entities also is a fully described object so knowledge graph information can be expanded very deeply depending on the knowledge that is relevant for a specific context. Since the information is stored on a graph database it can be easily queried using a simple query language.
Here you see another example with one more level of related information on one of the nodes (example only).
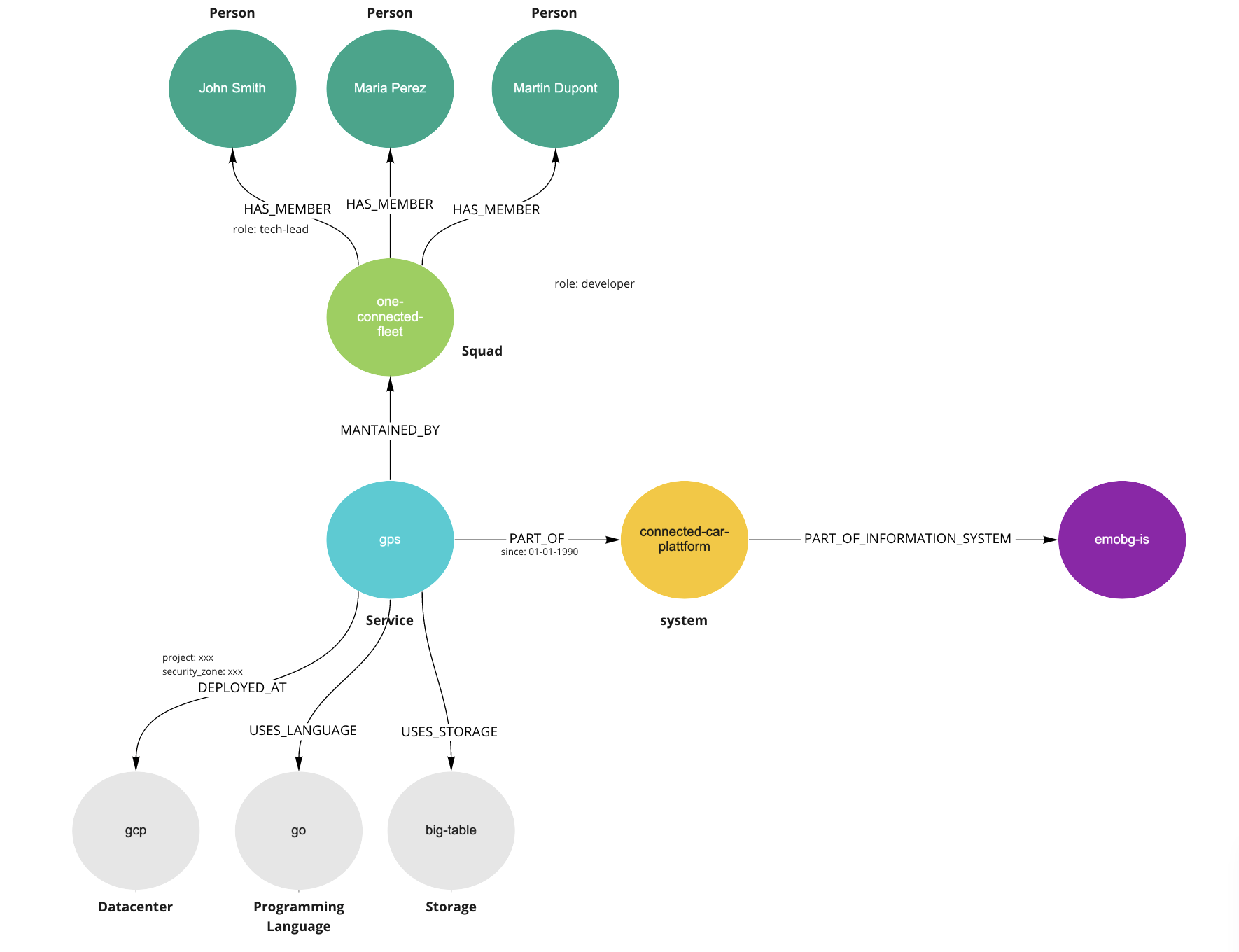
With this approach of structuring information you can query and get automated architecture views with different actors and entity types a required that don’t need to be maintained on an isolated way and adapt the view depending on the specific need. Information discovery and understanding is dramatically improved since complexity can be fully adjusted.
Entities, relations and schemas can contain technical and business information alike so the richness and depth of the knowledge graph that can be created is enormous while mantaining an easy structure.
Example entities relations:
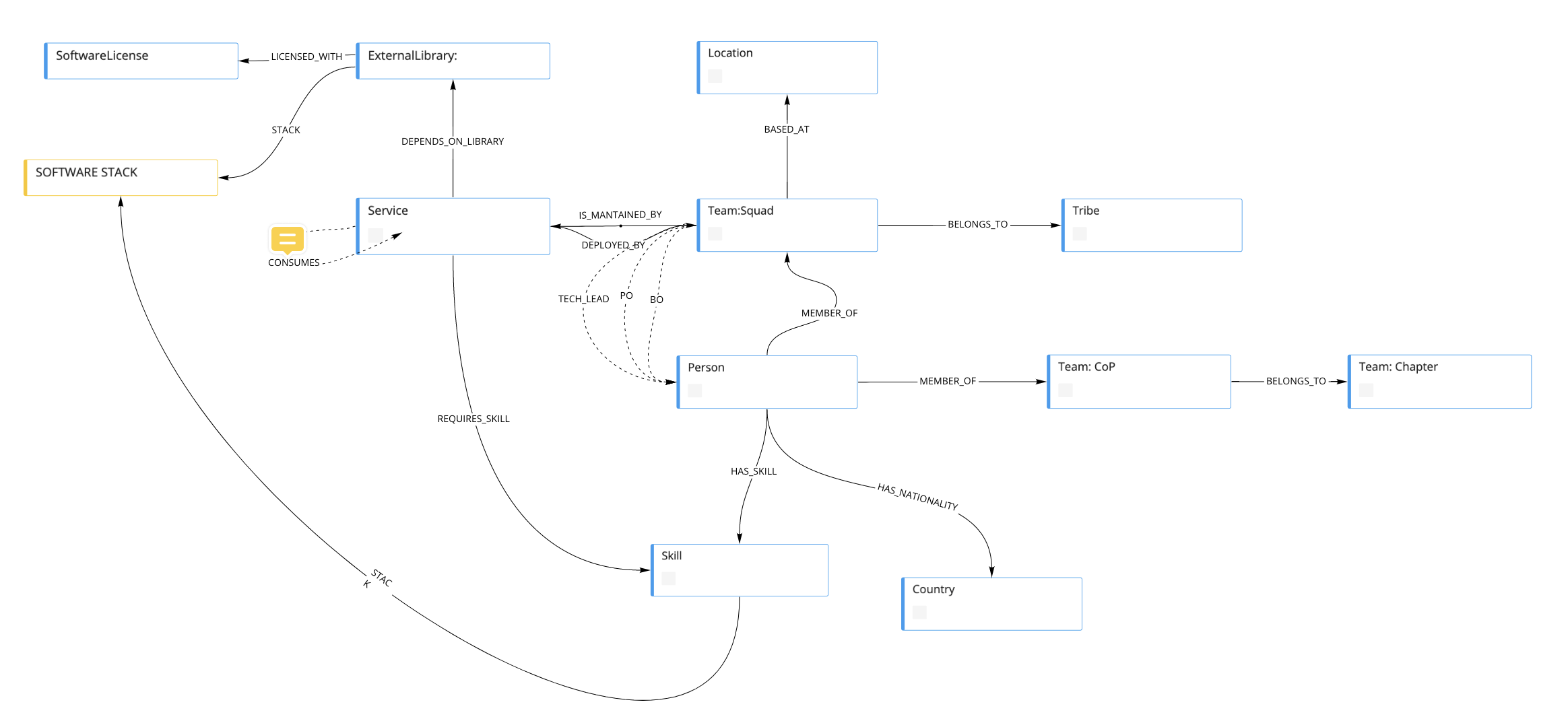
With this post I wanted to explain a bit more in detail how we are trying to automate our service catalog and documentation. There are still other specifics that not covered on this post but I believe it has enough detail to explain the approach we have taken.
Thanksfor reading so so far and I hope you found some helpful information. If you have questions/comments/feedback I will be happy to hear!